이 글은 BigQuery에서 중첩 데이터(JSON, ARRAY, STRUCT)를 처음 다루는 학습자를 위한 실습 기록입니다.
문제는 일반적인 SQL은 익숙해도 BigQuery의 ARRAY와 STRUCT 같은 중첩 데이터 구조를 어떻게 조회하고 풀어내는지 처음에는 감이 잘 오지 않는다는 점입니다.
이 글을 통해 JSON 데이터를 BigQuery에 적재하고, ARRAY와 STRUCT를 UNNEST로 풀어 분석 가능한 형태로 변환하는 전체 과정을 직접 따라할 수 있습니다.
이 글의 핵심 질문
BigQuery에서 JSON 기반의 ARRAY와 STRUCT 데이터를 어떻게 조회하고 분석 가능한 형태로 변환할 수 있는가?
실습 환경
- Cloud: Google Cloud Platform
- 서비스: BigQuery
- Dataset:
fruit_store,racing - 데이터 유형: JSON, ARRAY, STRUCT(RECORD)
- 주요 테이블:
fruit_details,race_results - 핵심 함수:
UNNEST(),CROSS JOIN,SUM(),COUNT()
아키텍처
이번 실습의 핵심 구조는 단순한 2차원 테이블이 아닙니다. JSON 파일이 Cloud Storage를 통해 BigQuery로 적재되고, 그 안에는 ARRAY와 STRUCT 같은 중첩 구조가 포함됩니다. 이후 SQL에서 UNNEST()를 사용해 이 구조를 펼치고, 일반적인 집계·필터·정렬이 가능한 평탄화된 결과로 바꾸는 흐름입니다.
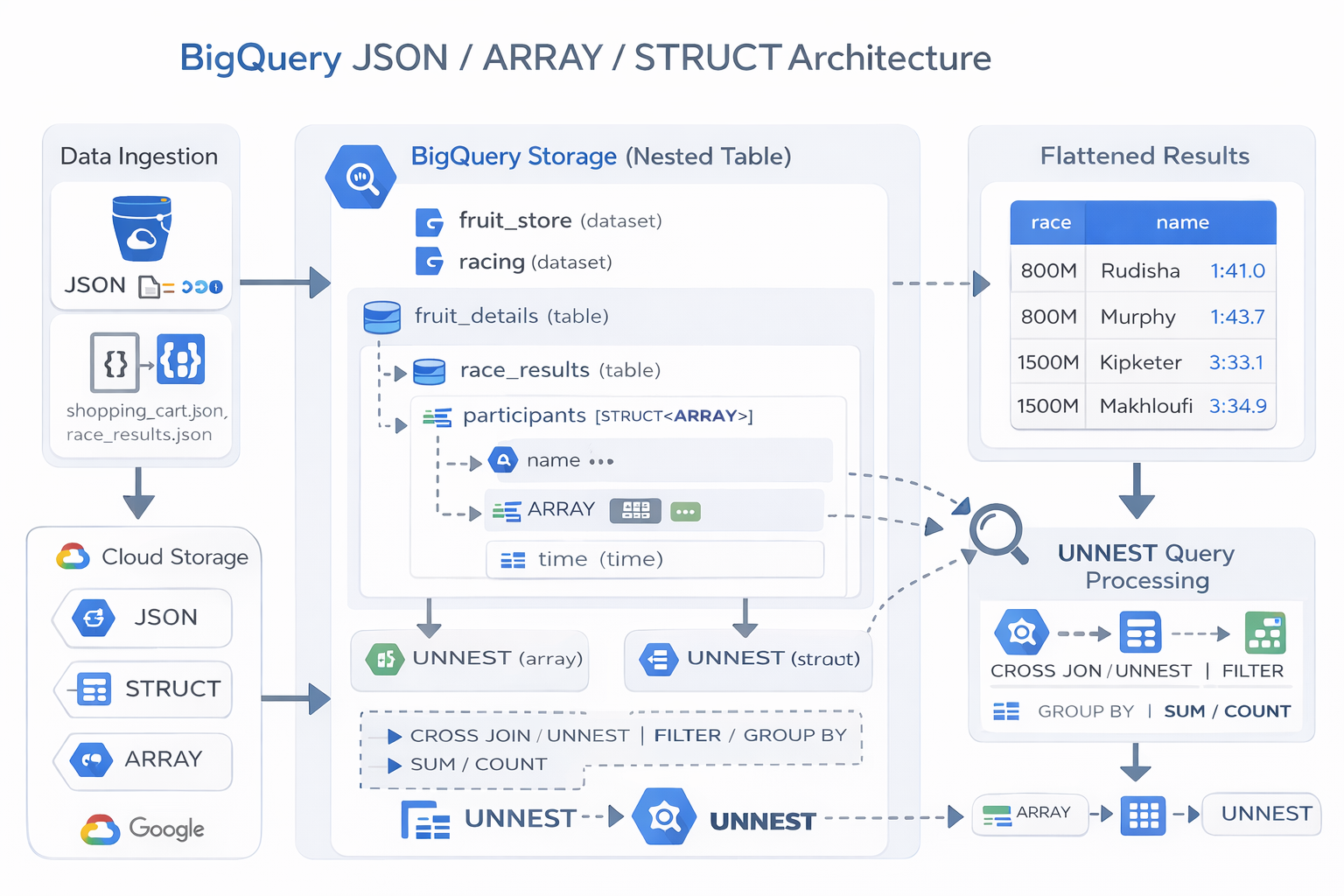
JSON / GCS → BigQuery Nested Table → STRUCT + ARRAY → UNNEST Query → Flattened Results
전체 흐름
이번 실습은 크게 5단계로 진행됩니다.
fruit_storeDataset 생성- ARRAY 개념 이해 및 JSON 테이블 적재
- STRUCT 개념 이해 및 중첩 스키마 생성
race_results테이블에서 STRUCT/ARRAY 구조 확인UNNEST()로 데이터를 펼쳐 실제 분석 수행
즉, 이번 실습의 목적은 단순 SELECT가 아니라 BigQuery의 중첩 데이터 구조를 “이해하고 펼치는 법”을 익히는 것입니다.
■ 강사 설명
실습은 먼저 간단한 과일 예제로 ARRAY를 소개한 뒤, JSON 파일을 BigQuery에 적재해 실제 배열 구조를 확인하도록 구성됩니다. 이후 러너의 랩 타임 예제를 통해 STRUCT와 ARRAY가 결합된 중첩 구조를 만들고, 마지막에는 UNNEST로 그 구조를 풀어 실제 SQL 분석을 수행합니다.
즉, 이 실습은 BigQuery의 고유 기능인 nested and repeated fields를 다루는 입문 과정이라고 보는 것이 맞습니다.
■ 내가 이해한 핵심
이번 실습의 본질은 아래 한 문장으로 정리됩니다.
BigQuery는 테이블 안에 또 다른 구조를 담고, 그것을 SQL로 직접 분석할 수 있다
일반적인 관계형 데이터베이스에서는 배열이나 객체 구조를 만나면 보통 여러 테이블로 쪼개고 JOIN을 생각합니다. 하지만 BigQuery는 ARRAY와 STRUCT를 같은 테이블 안에 자연스럽게 담고, 필요할 때만 펼쳐서 분석할 수 있습니다. 이것이 이번 실습의 핵심 차이입니다.
■ 내가 실제로 겪은 문제
처음 가장 헷갈렸던 부분은 이 쿼리였습니다.
SELECT race, participants.name
FROM racing.race_results
직관적으로는 될 것 같지만, 실제로는 오류가 납니다.
Cannot access field name on a value with type
ARRAY<STRUCT<name STRING, splits ARRAY<FLOAT64>>>
원인은 분명합니다. participants는 단순 필드가 아니라 ARRAY 안에 들어 있는 STRUCT이기 때문입니다. 즉, 바로 점 접근을 할 수 없고 먼저 펼쳐야 합니다. 이 실수를 통해 BigQuery에서는 “중첩 구조를 먼저 이해한 뒤 쿼리해야 한다”는 점이 아주 분명해졌습니다. :contentReference[oaicite:0]{index=0}
실습 단계
1단계. fruit_store Dataset 생성
목적: 중첩 데이터 연습용 공간을 만드는 단계입니다.
BigQuery에서 프로젝트 오른쪽의 View actions 아이콘을 눌러 Create dataset을 선택합니다. Dataset 이름은 fruit_store로 지정하고 나머지 옵션은 기본값으로 둡니다. 생성이 끝나면 이제 ARRAY와 JSON 예제를 담을 공간이 마련됩니다. 실습 문서도 이 과정을 첫 단계로 안내합니다. :contentReference[oaicite:1]{index=1}
이 단계는 단순 준비처럼 보이지만 중요합니다. BigQuery에서 중첩 데이터 실습은 일반 테이블 실습과 달리 별도 구조를 많이 만들게 되므로, Dataset을 분리해 두는 습관이 이후 관리에 큰 도움이 됩니다.
2단계. ARRAY 개념을 SQL로 먼저 이해하기
목적: BigQuery의 배열이 무엇인지 감각적으로 익히는 단계입니다.
먼저 아래 쿼리를 실행합니다.
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry'] AS fruit_array
이 결과는 행이 여러 개 생기는 것이 아니라, 한 행 안에 여러 값이 들어 있는 ARRAY 필드로 표시됩니다. 실습 문서는 이를 “배열은 대괄호 [ ] 안에 들어 있는 값의 리스트”라고 설명합니다. BigQuery UI에서는 배열 값을 세로로 펼쳐 보여주지만, 여전히 한 행에 속한 값들입니다. :contentReference[oaicite:2]{index=2}
그 다음 아래처럼 서로 다른 타입을 한 배열에 넣으면 오류가 납니다.
#standardSQL
SELECT
['raspberry', 'blackberry', 'strawberry', 'cherry', 33] AS fruit_array
여기서 중요한 규칙을 배웁니다. ARRAY는 반드시 같은 데이터 타입만 담을 수 있다는 점입니다. 문자열 배열에는 숫자를 함께 넣을 수 없습니다. 이 규칙은 뒤에서 splits 배열처럼 숫자만 담는 구조를 이해할 때 매우 중요합니다. :contentReference[oaicite:3]{index=3}
3단계. JSON 파일을 BigQuery 테이블로 적재하고 REPEATED 필드 확인
목적: 실제 JSON 적재 후 배열 필드가 스키마에 어떻게 표현되는지 확인하는 단계입니다.
이제 fruit_store Dataset에서 Create table을 선택합니다. Source는 Google Cloud Storage, 파일 경로는 shopping_cart.json, 형식은 JSONL (Newline delimited JSON), 테이블 이름은 fruit_details로 지정합니다. Schema는 Auto detect를 켠 뒤 Create table을 누릅니다. :contentReference[oaicite:4]{index=4}
테이블이 만들어진 뒤 Schema 탭을 확인하면 fruit_array 필드가 REPEATED로 표시됩니다. 이것이 BigQuery에서 배열을 저장하는 방식입니다. 즉, JSON에서 여러 값을 담고 있던 필드는 BigQuery 스키마에서 REPEATED 필드로 매핑됩니다. :contentReference[oaicite:5]{index=5}
이 단계에서 중요한 깨달음은, BigQuery가 JSON 구조를 단순 텍스트로 저장하는 것이 아니라 구조를 이해한 상태로 스키마에 반영한다는 점입니다.
4단계. STRUCT 개념을 작은 SQL 예제로 먼저 이해하기
목적: ARRAY와 달리 여러 타입과 필드를 담을 수 있는 STRUCT를 이해하는 단계입니다.
아래 쿼리를 실행합니다.
#standardSQL
SELECT STRUCT("Rudisha" as name, 23.4 as split) as runner
결과는 runner.name, runner.split처럼 점 표기법으로 접근 가능한 구조로 나타납니다. 이것이 STRUCT입니다. 실습 문서는 STRUCT를 “여러 필드명과 데이터 타입을 담을 수 있는 컨테이너”라고 설명합니다. :contentReference[oaicite:6]{index=6}
그리고 아래처럼 STRUCT 안에 ARRAY를 넣을 수도 있습니다.
#standardSQL
SELECT STRUCT("Rudisha" as name, [23.4, 26.3, 26.4, 26.1] as splits) AS runner
이 예제가 중요한 이유는 이후 race_results 테이블 구조를 그대로 예고하기 때문입니다. 즉, STRUCT는 객체 역할을 하고, 그 안에 ARRAY는 반복되는 값 목록으로 들어갈 수 있습니다. BigQuery 중첩 데이터의 핵심 패턴이 바로 이것입니다. :contentReference[oaicite:7]{index=7}
5단계. racing Dataset과 race_results 테이블 생성
목적: STRUCT + ARRAY가 함께 들어 있는 실제 JSON 데이터를 BigQuery에 적재하는 단계입니다.
새 Dataset racing을 만들고, 테이블 이름을 race_results로 설정합니다. 소스 파일은 race_results.json, 파일 형식은 JSONL입니다. 이번에는 Auto detect만 쓰지 않고, Edit as text를 켠 뒤 스키마를 직접 입력합니다. 실습 문서는 아래 구조를 요구합니다.
race: STRINGparticipants: RECORD / REPEATED- participants.name : STRING
- participants.splits : FLOAT / REPEATED
즉, participants는 STRUCT(RECORD)이고, 그 안에 splits라는 배열이 들어 있는 중첩 구조입니다. 테이블이 생성된 뒤 스키마를 보면 participants는 RECORD, splits는 REPEATED로 표시됩니다. 실습 문서도 바로 이 점을 질문 형태로 확인시킵니다. :contentReference[oaicite:8]{index=8}
이 단계가 중요한 이유는 중첩 구조를 “머리로만” 이해하는 것이 아니라, 실제 BigQuery 스키마 화면에서 어떻게 표현되는지 확인할 수 있기 때문입니다.
6단계. 중첩 구조를 그냥 접근했을 때 왜 실패하는지 이해하기
목적: UNNEST가 왜 필요한지 오류를 통해 배우는 단계입니다.
먼저 아래 쿼리를 실행합니다.
#standardSQL
SELECT * FROM racing.race_results
이 쿼리는 중첩 구조를 가진 원본 행을 그대로 보여줍니다. 페이지 9 이미지에서도 race 값은 하나인데, participants.name과 participants.splits가 세로로 이어져 나오는 모습을 볼 수 있습니다. 즉, 하나의 행 안에 여러 러너와 여러 split 값이 들어 있는 구조입니다. :contentReference[oaicite:9]{index=9}
그 다음 이름만 뽑으려고 아래처럼 접근하면 오류가 납니다.
#standardSQL
SELECT race, participants.name
FROM racing.race_results
왜냐하면 participants는 단일 STRUCT가 아니라 ARRAY<STRUCT>이기 때문입니다. 즉, 먼저 이 배열을 행으로 풀어야 합니다. 이 단계는 BigQuery 중첩 데이터의 가장 중요한 관문입니다. “점 표기법으로 안 되는 이유”를 이해해야 이후 모든 UNNEST 쿼리가 자연스럽게 보입니다. :contentReference[oaicite:10]{index=10}
7단계. UNNEST와 CROSS JOIN으로 STRUCT 펼치기
목적: ARRAY 안의 STRUCT를 개별 행으로 풀어 일반 SQL처럼 다루는 단계입니다.
실습 문서는 먼저 CROSS JOIN 개념을 설명합니다. 전통적인 관계형 SQL에서는 두 테이블을 JOIN해서 관계를 맞추듯이, BigQuery에서는 한 행 안에 중첩된 STRUCT 배열을 “행으로 풀어” 상위 필드와 연결해야 합니다.
아래 쿼리가 그 핵심입니다.
#standardSQL
SELECT race, participants.name
FROM racing.race_results
CROSS JOIN
race_results.participants
그리고 더 실무적인 형태로는 아래처럼 alias와 UNNEST를 쓰는 방식이 권장됩니다.
#standardSQL
SELECT race, p.name
FROM racing.race_results AS r,
UNNEST(r.participants) AS p
이제 결과는 800M race에 대해 Rudisha, Makhloufi, Murphy 등 각 러너가 개별 행으로 출력됩니다. 실습 문서도 이것이 correlated cross join이며, 카테시안 곱처럼 모든 race와 모든 참가자가 섞이는 것이 아니라, 각 행에 속한 participants만 펼쳐지는 구조라고 설명합니다. :contentReference[oaicite:11]{index=11}
이 단계에서 반드시 기억해야 할 핵심은 이것입니다.
UNNEST는 BigQuery 중첩 데이터 분석의 시작점이다
8단계. UNNEST로 ARRAY를 풀어 필터와 집계 적용하기
목적: 배열 값을 실제 SQL 분석 대상으로 바꾸는 단계입니다.
먼저 간단한 문자열 배열을 펼칩니다.
#standardSQL
SELECT * FROM
UNNEST(['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian']) AS unnested_array_of_names
이 결과는 8개의 개별 행으로 반환됩니다. 실습 문서도 “배열을 평탄화(flattening)했다”고 설명합니다. 그리고 여기에 WHERE를 붙이면 일반 SQL처럼 필터링할 수 있습니다.
#standardSQL
SELECT * FROM
UNNEST(['Rudisha','Makhloufi','Murphy','Bosse','Rotich','Lewandowski','Kipketer','Berian']) AS unnested_array_of_names
WHERE unnested_array_of_names LIKE 'M%'
결과는 Makhloufi, Murphy 두 행만 나옵니다. 즉, 배열은 그 자체로는 리스트이지만, UNNEST 이후에는 일반 테이블처럼 WHERE, ORDER BY, GROUP BY를 쓸 수 있습니다. :contentReference[oaicite:12]{index=12}
이제 이 개념을 실제 race_results에 적용하면 더 강력해집니다. 예를 들어 러너 이름이 R로 시작하는 사람들의 총 레이스 시간을 구하려면 participants 배열과 splits 배열을 모두 UNNEST해야 합니다.
#standardSQL
SELECT
p.name,
SUM(split_times) as total_race_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_times
WHERE p.name LIKE 'R%'
GROUP BY p.name
ORDER BY total_race_time ASC;
실습 문서 결과에 따르면 Rudisha와 Rotich가 반환되며, 더 빠른 total_race_time이 먼저 나옵니다. 즉, 중첩된 배열을 모두 풀면 일반적인 집계 분석이 가능해집니다. :contentReference[oaicite:13]{index=13}
마지막으로 가장 빠른 랩타임 23.2초를 기록한 선수를 찾는 쿼리도 같은 원리입니다.
#standardSQL
SELECT
p.name,
split_time
FROM racing.race_results AS r
, UNNEST(r.participants) AS p
, UNNEST(p.splits) AS split_time
WHERE split_time = 23.2;
실습 문서 결과는 Kipketer입니다. 이 예제가 중요한 이유는, BigQuery에서는 “배열 안의 특정 값”도 SQL 조건으로 직접 필터링할 수 있음을 보여주기 때문입니다. :contentReference[oaicite:14]{index=14}
실습 증거
1. fruit_array의 동일 타입 규칙
문자열 배열에 숫자 33을 섞었을 때 Array elements of types {INT64, STRING} do not have a common supertype 오류가 발생합니다. 이는 ARRAY가 동일 타입만 허용한다는 직접 증거입니다. :contentReference[oaicite:15]{index=15}
2. participants는 STRUCT(RECORD), splits는 ARRAY(REPEATED)
페이지 8 스키마 화면은 participants가 RECORD이고, participants.splits가 REPEATED FLOAT임을 보여줍니다. 즉, STRUCT 안에 ARRAY가 들어 있는 전형적인 중첩 구조라는 증거입니다. :contentReference[oaicite:16]{index=16}
3. participants.name 직접 접근 시 오류
페이지 9는 Cannot access field name on a value with type ARRAY<STRUCT...> 오류를 보여줍니다. 이는 UNNEST가 왜 필요한지 설명하는 핵심 증거입니다. :contentReference[oaicite:17]{index=17}
4. UNNEST 후 총 8명의 러너 집계 가능
실습 문서의 COUNT 예제는 UNNEST(r.participants)를 사용해 총 8명의 러너를 계산합니다. 이는 중첩 데이터가 평탄화 이후 일반적인 COUNT 분석에 사용될 수 있음을 보여줍니다. :contentReference[oaicite:18]{index=18}
트러블슈팅
문제 증상:participants.name처럼 중첩 필드에 바로 접근하려고 하면 오류가 발생한다.
원인 분석:
participants는 단일 STRUCT가 아니라 ARRAY<STRUCT> 이므로, 먼저 배열을 풀지 않으면 내부 필드에 접근할 수 없다.
확인 방법:
에러 메시지에 Cannot access field name on a value with type ARRAY<STRUCT...>가 있는지 확인한다.
해결 방법:UNNEST(r.participants)를 사용해 participants 배열을 먼저 펼친 뒤 alias를 통해 필드에 접근한다.
재발 방지 방법:
BigQuery 스키마에서 Type과 Mode를 먼저 확인하고, REPEATED라면 항상 UNNEST가 필요할 수 있음을 먼저 떠올린다.
문제 증상:
ARRAY 안에 서로 다른 타입을 넣었더니 쿼리가 실패한다.
원인 분석:
ARRAY는 하나의 공통 데이터 타입만 허용하기 때문이다.
확인 방법:
에러 메시지에 do not have a common supertype가 나오는지 확인한다.
해결 방법:
모든 배열 원소를 같은 타입으로 통일한다.
재발 방지 방법:
배열을 만들기 전에 문자열 배열인지, 숫자 배열인지 먼저 정의하고 타입을 혼합하지 않는다.
실무 핵심 포인트
이번 실습의 핵심은 아래 한 문장으로 정리할 수 있습니다.
BigQuery는 비정형에 가까운 JSON 구조를 그대로 저장하고, 필요할 때 SQL로 구조화해 분석할 수 있다
즉, 일반적인 데이터베이스처럼 처음부터 모든 것을 정규화하지 않아도 됩니다. 로그 데이터, 이벤트 데이터, 사용자 행동 데이터처럼 JSON 기반 구조가 많은 현대 분석 환경에서는 ARRAY와 STRUCT를 이해하는 것이 곧 실무 경쟁력입니다.
특히 GA4, API 응답 로그, 애플리케이션 이벤트 데이터는 대부분 중첩 구조를 포함합니다. 이번 실습은 그 구조를 다루는 가장 기본이자 중요한 출발점입니다.
결론
핵심 원칙
BigQuery에서 JSON·ARRAY·STRUCT 데이터를 분석하려면 구조를 먼저 이해하고, REPEATED 필드는 UNNEST로 평탄화한 뒤 SQL을 적용해야 한다.
실무 적용 시 주의점
- ARRAY는 같은 타입만 허용됨
- STRUCT는 여러 필드와 타입을 담을 수 있음
- REPEATED 필드는 거의 항상 UNNEST가 필요함
- 중첩 구조는 오류 메시지를 읽는 습관이 중요함
- 스키마의 Type과 Mode를 먼저 보면 대부분의 쿼리 오류를 줄일 수 있음
다음 학습 단계 제안
다음에는 GA4 이벤트 데이터처럼 실제 JSON 로그 구조를 BigQuery에서 분석하거나, UNNEST 결과를 Looker Studio와 연결해 시각화해보면 좋습니다.
'서버 구축·실습' 카테고리의 다른 글
| BigQuery에서 날짜 파티션 테이블을 만드는 방법: 쿼리 비용과 성능을 줄이는 실습 가이드 (0) | 2026.03.27 |
|---|---|
| BigQuery에서 JOIN 오류가 발생하는 이유와 해결 방법 (데이터 조인 실습 완전 가이드) (0) | 2026.03.26 |
| GCP Vision API로 이미지에서 텍스트 추출하고 번역하는 방법 (OCR 실습 완전 가이드) (0) | 2026.03.25 |
| GCP AutoML로 이미지 분류 모델 만드는 방법 (Cloud Vision API 실습 기반 완전 가이드) (0) | 2026.03.25 |
| GCP BigQuery에서 CSV·GCS·Google Sheets 데이터를 적재하는 방법 (실습 기반 완전 가이드) (0) | 2026.03.24 |



