문제는 JOIN 문법 자체는 이해해도, 실제 데이터에서는 중복 키와 잘못된 조인 유형 때문에 결과가 왜곡되기 쉽다는 점입니다.
이 글을 통해 비고유 키, INNER JOIN 손실, LEFT JOIN의 NULL, CROSS JOIN 증폭, 그리고 DISTINCT 기반 해결 방법을 실제 예제로 따라할 수 있습니다.
이 글의 핵심 질문
BigQuery에서 JOIN 결과가 틀어지는 이유는 무엇이며, 어떻게 정확하게 해결할 수 있는가?
실습 환경
- Cloud: Google Cloud Platform
- 서비스: BigQuery
- 주요 데이터셋:
data-to-insights.ecommerce,ecommerce - 주요 테이블:
all_sessions_raw,products,site_wide_promotion - 핵심 주제: 비고유 키, JOIN 타입, 데이터 손실, 중복 제거
아키텍처
이번 실습의 핵심 구조는 두 개의 서로 다른 데이터 소스를 SKU 기준으로 조인하는 흐름입니다. 하나는 웹 로그 성격의 all_sessions_raw 테이블이고, 다른 하나는 재고 정보가 들어 있는 products 테이블입니다. 문제는 왼쪽 테이블의 SKU가 항상 유일하지 않다는 점이며, 이 상태에서 JOIN을 수행하면 데이터가 사라지거나, 반대로 곱셈처럼 폭증할 수 있습니다.
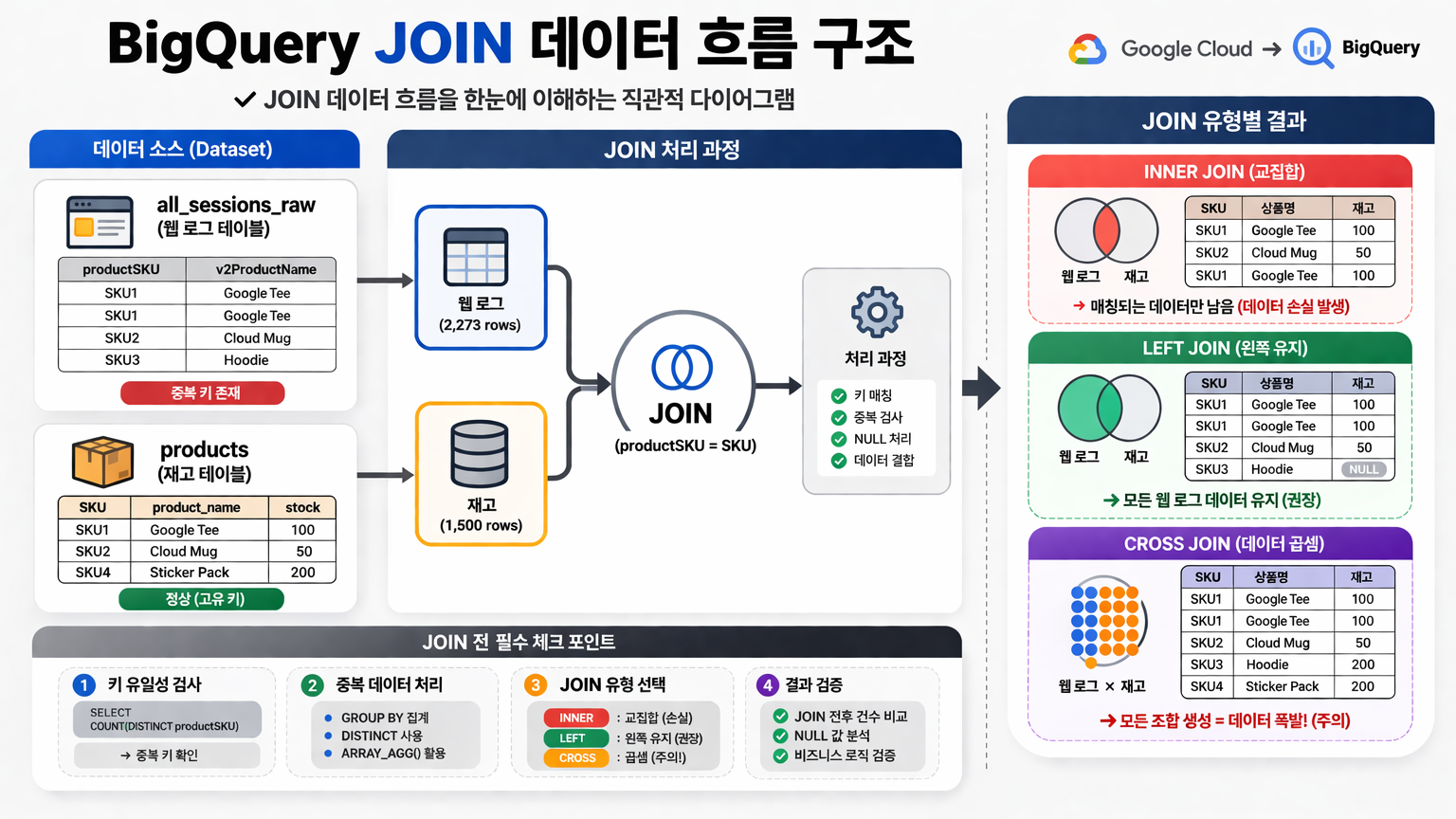
all_sessions_raw + products → JOIN 처리 → INNER / LEFT / CROSS 결과 비교 → 중복 제거 및 검증
전체 흐름
이번 실습은 크게 5단계로 진행됩니다.
- 웹 로그와 재고 데이터의 키 구조 확인
- SKU와 상품명이 실제로 유일한지 검증
- JOIN 수행 후 발생하는 중복·손실 문제 확인
- LEFT JOIN과 NULL 필터로 누락 데이터 찾기
- DISTINCT, ARRAY_AGG 등으로 조인 전 데이터를 정리하기
즉, 이번 실습의 핵심은 SQL 문법 자체가 아니라 JOIN 전에 데이터 관계를 먼저 검증하는 사고방식을 익히는 데 있습니다.
■ 강사 설명
실습은 먼저 all_sessions_raw 테이블의 productSKU와 상품명(v2ProductName)을 살펴보며, 실제 조인 키로 쓸 수 있는 필드가 무엇인지 검토하는 것에서 시작합니다. 이후 재고 테이블 products와 조인했을 때 왜 재고 수량이 3배가 되거나, 일부 SKU가 사라지는지를 직접 확인하게 합니다. 마지막에는 FULL JOIN, CROSS JOIN, ARRAY_AGG 기반 중복 제거까지 이어지며, JOIN 문제의 전형적인 함정을 단계적으로 보여줍니다. :contentReference[oaicite:0]{index=0}
■ 내가 이해한 핵심
이번 실습의 본질은 아래 한 문장으로 정리됩니다.
JOIN 문제의 대부분은 SQL 문법이 아니라, 키의 유일성과 데이터 관계를 모른 채 조인을 수행하는 데서 시작된다
즉, productSKU라는 컬럼 이름만 보고 “당연히 유일하겠지”라고 가정하면 안 됩니다. 조인은 연결이 아니라 사실상 곱셈에 가까운 연산이기 때문에, 키가 중복된 상태로 들어가면 결과는 쉽게 왜곡됩니다.
■ 내가 실제로 겪은 문제
실습에서 가장 먼저 인상 깊었던 부분은 특정 SKU 하나를 조인했을 때 재고가 154가 아니라 462처럼 보인다는 점이었습니다. 처음에는 SUM 계산을 잘못한 줄 알았지만, 원인은 훨씬 근본적이었습니다.
같은 SKU가 웹 로그 테이블 안에 여러 행으로 존재했고, 그 상태에서 재고 테이블과 조인되면서 같은 재고가 반복 매칭된 것입니다.
즉, 조인 후 숫자가 이상하면 먼저 집계 함수보다 조인 전 데이터의 키 구조를 의심해야 한다는 교훈을 얻게 됩니다.
실습 단계
1단계. 실습용 Dataset 준비 및 공개 프로젝트 고정
목적: 내 프로젝트 안에 작업용 Dataset을 만들고, 공개 데이터셋 프로젝트를 탐색기에서 볼 수 있게 준비하는 단계입니다.
먼저 BigQuery에서 내 프로젝트 아래에 ecommerce Dataset을 생성합니다. 이후 + ADD를 눌러 Star a project by name를 선택하고, 프로젝트명으로 data-to-insights를 입력해 고정합니다. 그러면 왼쪽 탐색기에서 data-to-insights.ecommerce 아래의 실습용 공개 테이블을 조회할 수 있습니다. 실습 문서도 이 공개 프로젝트를 먼저 고정하지 않으면 웹 UI에서 보이지 않는다고 설명합니다. :contentReference[oaicite:1]{index=1}
이 단계는 단순 준비처럼 보이지만 중요합니다. 이후 JOIN 비교 대상이 되는 all_sessions_raw와 products가 서로 다른 데이터셋에 있기 때문에, 시작부터 데이터 위치를 정확히 파악해야 실습 흐름이 끊기지 않습니다.
2단계. 조인 키 후보인 productSKU와 상품명 구조 확인
목적: 어떤 필드를 조인 기준으로 사용할 수 있을지, 그리고 그 필드가 실제로 유일한지 검토하는 단계입니다.
먼저 아래 쿼리로 웹사이트의 상품 SKU와 상품명을 살펴봅니다.
#standardSQL
SELECT DISTINCT
productSKU,
v2ProductName
FROM `data-to-insights.ecommerce.all_sessions_raw`
실습 문서에 따르면 이 결과는 총 2,273개 레코드를 반환합니다. 하지만 이것이 곧 2,273개의 유일한 SKU라는 뜻은 아닙니다. 이어서 SKU만 따로 DISTINCT 하면 실제 고유 SKU 수는 1,909개로 줄어듭니다. 즉, “SKU + 상품명 조합”은 2,273개인데 “SKU만 고유하게 세면” 1,909개라는 뜻입니다. 실습 문서도 바로 이 차이를 통해 중복 가능성을 문제로 제시합니다. :contentReference[oaicite:2]{index=2}
이 단계의 핵심은 아주 분명합니다. 조인 키로 보이는 필드는 먼저 COUNT DISTINCT로 검증해야 한다는 점입니다.
3단계. 상품명과 SKU가 각각 얼마나 유일하지 않은지 확인
목적: productSKU와 v2ProductName 중 어느 쪽이 더 신뢰 가능한 키인지, 또는 둘 다 문제가 있는지를 확인하는 단계입니다.
먼저 하나의 상품명이 여러 SKU를 가지는지 봅니다.
#standardSQL
SELECT
DISTINCT
COUNT(DISTINCT productSKU) AS SKU_count,
STRING_AGG(DISTINCT productSKU LIMIT 5) AS SKU,
v2ProductName
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE productSKU IS NOT NULL
GROUP BY v2ProductName
HAVING SKU_count > 1
ORDER BY SKU_count DESC
이 결과는 같은 상품명 아래 여러 SKU가 존재함을 보여줍니다. 실습 문서는 이것을 제품 변형(예: 색상, 사이즈 등) 때문에 어느 정도는 예상 가능한 현상이라고 설명합니다. 즉, 상품명은 조인 키로 쓰기에 적합하지 않습니다. :contentReference[oaicite:3]{index=3}
하지만 더 심각한 문제는 반대 방향에서 발생합니다. 하나의 SKU에 여러 상품명이 연결된 경우입니다.
#standardSQL
SELECT
DISTINCT
COUNT(DISTINCT v2ProductName) AS product_count,
STRING_AGG(DISTINCT v2ProductName LIMIT 5) AS product_name,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE v2ProductName IS NOT NULL
GROUP BY productSKU
HAVING product_count > 1
ORDER BY product_count DESC
실습 문서는 이 결과를 데이터 품질 문제로 해석합니다. 실제로 동일 SKU에 철자 차이나 표현 차이가 있는 유사 상품명이 여러 개 붙어 있는 사례가 존재합니다. 즉, productSKU도 이 테이블에서는 완전히 깨끗한 1:1 키가 아닙니다. :contentReference[oaicite:4]{index=4}
이 단계가 중요한 이유는 조인 전에 데이터 관계를 다음처럼 분류할 수 있게 해주기 때문입니다.
- 1:1 관계인지
- 1:N 관계인지
- N:N 관계 위험이 있는지
4단계. 실제 JOIN 후 왜 재고 수량이 3배로 보이는지 확인
목적: 비고유 키 상태에서 JOIN이 어떤 문제를 일으키는지 실제 숫자로 확인하는 단계입니다.
실습 문서에서는 문제 SKU로 GGOEGPJC019099를 예로 듭니다. 먼저 웹 로그 테이블에서 이 SKU가 어떤 상품명으로 나타나는지 봅니다.
#standardSQL
SELECT DISTINCT
v2ProductName,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE productSKU = 'GGOEGPJC019099'
결과를 보면 같은 SKU에 대해 유사하지만 서로 다른 상품명이 3개 가까이 연결되어 있습니다. 반면 재고 테이블에서는 아래 쿼리로 확인했을 때 이 SKU가 단 하나의 행으로 존재합니다.
#standardSQL
SELECT * FROM `data-to-insights.ecommerce.products`
WHERE SKU = 'GGOEGPJC019099'
실습 문서 기준으로 이 SKU의 재고는 154입니다. :contentReference[oaicite:5]{index=5}
이제 두 테이블을 조인하면 문제가 드러납니다.
#standardSQL
SELECT DISTINCT
website.v2ProductName,
website.productSKU,
inventory.stockLevel
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE productSKU = 'GGOEGPJC019099'
결과에서는 stockLevel 154가 세 번 반복됩니다. 이후 이를 SUM 하면 462가 됩니다. 실습 문서도 이것을 “triple counting”이며 의도하지 않은 cross join 성격의 증폭이라고 설명합니다. :contentReference[oaicite:6]{index=6}
이 단계의 핵심은 분명합니다. 한쪽 키가 중복된 상태에서 조인하면 숫자는 쉽게 불어나며, 이후 SUM은 그 왜곡을 더 키운다는 점입니다.
5단계. JOIN 전에 DISTINCT SKU만 남기고 다시 생각하기
목적: 조인 전 중복 키를 제거해야 하는 이유를 확인하는 단계입니다.
실습 문서는 먼저 웹 로그 테이블의 고유 SKU 수를 세어봅니다.
#standardSQL
SELECT
COUNT(DISTINCT website.productSKU) AS distinct_sku_count
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
결과는 1,909입니다. 즉, 최소한 SKU 기준으로 한 번 deduplicate한 뒤 조인을 생각해야 한다는 의미입니다. 실습 문서도 이 수치를 “distinct SKUs from the website dataset”라고 명시합니다. :contentReference[oaicite:7]{index=7}
이 단계는 단순 카운트처럼 보여도 매우 중요합니다. 조인을 하기 전 원천 데이터의 grain(행의 단위)을 먼저 맞춰야 하기 때문입니다. 웹 로그 테이블은 주문·조회 로그의 grain이고, 재고 테이블은 SKU 재고의 grain입니다. 이 grain mismatch를 정리하지 않으면 조인은 곧바로 왜곡됩니다.
6단계. INNER JOIN으로 왜 데이터가 사라지는지 확인
목적: 데이터가 증가하는 문제뿐 아니라, 반대로 사라지는 문제도 JOIN에서 자주 발생한다는 점을 확인하는 단계입니다.
아래 쿼리는 웹 로그의 distinct SKU와 재고 테이블을 INNER JOIN 합니다.
#standardSQL
SELECT DISTINCT
website.productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
이론상 1,909개 SKU가 다 나와야 할 것 같지만, 실습 문서에 따르면 실제 결과는 1,090개만 반환됩니다. 즉, 819개 SKU가 조인 후 사라집니다. :contentReference[oaicite:8]{index=8}
이유는 단순합니다. INNER JOIN은 양쪽에 모두 존재하는 키만 남기기 때문입니다. 즉, 재고 테이블에 없는 SKU는 웹 로그에 있더라도 결과에서 사라집니다.
이 단계는 매우 중요합니다. 많은 초보자가 “JOIN 후 레코드 수가 줄어든 이유”를 쿼리 오류로 생각하지만, 실제로는 INNER JOIN의 정상 동작일 수 있습니다. 문제는 사용 목적에 맞는 조인 유형을 선택했는가입니다.
7단계. LEFT JOIN과 NULL 필터로 누락 SKU 찾기
목적: 웹 로그를 기준으로 모든 SKU를 유지하면서, 재고 테이블에 없는 SKU만 따로 식별하는 단계입니다.
같은 쿼리를 LEFT JOIN으로 바꿉니다.
#standardSQL
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
LEFT JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
이제 웹 로그 기준 1,909개 SKU가 모두 유지됩니다. 그리고 inventory.SKU가 NULL인 행만 필터링하면 재고 테이블에 없는 SKU를 정확히 찾을 수 있습니다.
#standardSQL
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
LEFT JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE inventory.SKU IS NULL
실습 문서 기준으로 이 결과는 819개입니다. 즉, INNER JOIN에서 사라졌던 SKU 수와 정확히 일치합니다. :contentReference[oaicite:9]{index=9}
이 단계의 핵심은 다음과 같습니다.
- INNER JOIN: 교집합
- LEFT JOIN: 왼쪽 보존 + 오른쪽 누락을 NULL로 표시
즉, 데이터 손실을 조사할 때는 대부분 INNER JOIN보다 LEFT JOIN + NULL 필터가 훨씬 유용합니다.
8단계. RIGHT JOIN / FULL JOIN으로 반대 방향 누락과 전체 누락 확인
목적: 재고에는 있는데 웹 로그에는 없는 SKU까지 포함해, 양쪽의 불일치를 전체적으로 파악하는 단계입니다.
실습 문서는 먼저 RIGHT JOIN으로 재고 기준 누락을 봅니다.
#standardSQL
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
RIGHT JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE website.productSKU IS NULL
결과는 웹 로그에 없는 재고 SKU 2개입니다. 실습 문서는 이들이 신상품이거나 “in store only”일 수 있다고 설명합니다. 즉, 웹 로그는 과거 주문/조회 기반 데이터라 아직 판매되지 않은 상품은 나타나지 않을 수 있습니다. :contentReference[oaicite:10]{index=10}
이제 FULL JOIN을 사용하면 양쪽 누락을 한 번에 볼 수 있습니다.
#standardSQL
SELECT DISTINCT
website.productSKU AS website_SKU,
inventory.SKU AS inventory_SKU
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
FULL JOIN `data-to-insights.ecommerce.products` AS inventory
ON website.productSKU = inventory.SKU
WHERE website.productSKU IS NULL OR inventory.SKU IS NULL
실습 문서는 이 결과를 819 + 2 = 821개 SKU 불일치로 정리합니다. 즉, FULL JOIN은 양쪽 누락을 동시에 조사할 때 매우 유용합니다. :contentReference[oaicite:11]{index=11}
9단계. CROSS JOIN이 왜 위험한지 확인
목적: 조인 조건이 없거나, 사실상 곱셈 구조가 되면 데이터가 어떻게 폭증하는지 확인하는 단계입니다.
실습에서는 먼저 할인율 0.05 하나만 담긴 테이블을 생성합니다.
#standardSQL
CREATE OR REPLACE TABLE ecommerce.site_wide_promotion AS
SELECT .05 AS discount;
이후 clearance 상품에 CROSS JOIN을 적용합니다.
SELECT DISTINCT
productSKU,
v2ProductCategory,
discount
FROM `data-to-insights.ecommerce.all_sessions_raw` AS website
CROSS JOIN ecommerce.site_wide_promotion
WHERE v2ProductCategory LIKE '%Clearance%'
이 단계에서는 할인율 행이 1개라서 clearance 상품 개수만큼만 결과가 나옵니다. 하지만 할인율 테이블에 0.04, 0.03 두 행을 추가하면 총 3행이 되고, 같은 CROSS JOIN을 다시 수행했을 때 결과는 82가 아니라 246으로 늘어납니다. 실습 문서도 이것을 “원래 데이터가 3배 증폭된 것”으로 설명합니다. :contentReference[oaicite:12]{index=12}
즉, CROSS JOIN은 의도적으로 전체 조합을 만들 때만 써야 하며, 조인 관계를 모른 채 사용하면 가장 위험한 유형 중 하나입니다.
10단계. ARRAY_AGG로 SKU당 하나의 상품명만 남기기
목적: 조인 전에 SKU별 대표 상품명 하나만 남겨 중복 문제를 줄이는 단계입니다.
실습 문서는 마지막 해결책으로 SKU당 여러 상품명이 있는 경우 하나만 선택하는 패턴을 제시합니다.
#standardSQL
WITH product_query AS (
SELECT
DISTINCT
v2ProductName,
productSKU
FROM `data-to-insights.ecommerce.all_sessions_raw`
WHERE v2ProductName IS NOT NULL
)
SELECT k.* FROM (
SELECT ARRAY_AGG(x LIMIT 1)[OFFSET(0)] k
FROM product_query x
GROUP BY productSKU
);
핵심은 ARRAY_AGG(... LIMIT 1)[OFFSET(0)]입니다. SKU별로 상품명들을 배열로 모은 뒤 하나만 선택하는 방식입니다. 실습 문서도 이 방법으로 SKU당 하나의 product_name만 남겨 deduplicate할 수 있다고 설명합니다. :contentReference[oaicite:13]{index=13}
이 단계가 중요한 이유는, JOIN 오류를 “조인 뒤 수정”하는 것이 아니라 조인 전에 grain을 맞추는 방식으로 예방하기 때문입니다.
실습 증거
1. 2,273 조합 vs 1,909 고유 SKU
실습 문서는 productSKU와 상품명 조합은 2,273개지만, SKU만 DISTINCT 하면 1,909개라고 명시합니다. 이는 조인 후보 키가 이미 중복 상태라는 직접 증거입니다. :contentReference[oaicite:14]{index=14}
2. 특정 SKU 조인 시 재고 154가 462처럼 보이는 현상
문서의 dog frisbee 예시는 재고 154가 JOIN 후 세 번 반복되어 462처럼 집계되는 문제를 보여줍니다. 이는 비고유 키 조인이 왜 위험한지 보여주는 대표 증거입니다. :contentReference[oaicite:15]{index=15}
3. INNER JOIN 후 819개 SKU 누락
실습 문서는 1,909개 고유 SKU 중 INNER JOIN 결과가 1,090개뿐이며, 819개가 사라진다고 설명합니다. 이는 조인 타입 선택이 결과 해석에 직접 영향을 준다는 증거입니다. :contentReference[oaicite:16]{index=16}
4. FULL JOIN으로 총 821개 불일치 확인
LEFT JOIN 기반 누락 819개와 RIGHT JOIN 기반 누락 2개를 FULL JOIN으로 합쳐 총 821개 SKU 불일치를 확인하는 과정은, 양쪽 데이터 품질을 동시에 검증하는 실전 패턴입니다. :contentReference[oaicite:17]{index=17}
트러블슈팅
문제 증상:
JOIN 후 재고나 금액이 예상보다 커지고, 같은 값이 여러 번 반복된다.
원인 분석:
조인 키가 한쪽 또는 양쪽에서 유일하지 않아, 1:N 또는 N:N 관계가 발생했기 때문이다.
확인 방법:
JOIN 전에 COUNT(DISTINCT key), GROUP BY key HAVING COUNT(*) > 1로 키 중복을 먼저 확인한다.
해결 방법:
DISTINCT, GROUP BY, ARRAY_AGG 등을 이용해 조인 전에 키 단위를 정리한 뒤 다시 조인한다.
재발 방지 방법:
조인 전에는 반드시 “이 키가 양쪽에서 1:1인가?”를 먼저 점검한다.
문제 증상:
INNER JOIN 후 원래 있던 SKU들이 사라진다.
원인 분석:
INNER JOIN은 양쪽에 모두 존재하는 키만 반환하므로, 재고 테이블에 없는 SKU는 자동으로 제거된다.
확인 방법:
LEFT JOIN으로 바꾼 뒤 WHERE inventory.SKU IS NULL 조건으로 누락 SKU를 직접 확인한다.
해결 방법:
조사 목적이라면 LEFT JOIN을 사용하고, 누락 데이터는 NULL 기준으로 별도 관리한다.
재발 방지 방법:
집계 전후 레코드 수를 비교하고, INNER JOIN 사용 시 데이터 손실 가능성을 항상 염두에 둔다.
문제 증상:
CROSS JOIN 후 결과 행 수가 갑자기 몇 배로 증가한다.
원인 분석:
CROSS JOIN은 조인 조건 없이 모든 조합을 생성하므로, 작은 테이블 행 수만큼 원본이 곱해진다.
확인 방법:
조인 대상 테이블의 행 수를 먼저 확인하고, CROSS JOIN 결과 건수와 비교한다.
해결 방법:
의도한 전체 조합이 아니라면 CROSS JOIN을 피하고, 조인 관계와 필터 조건을 먼저 명확히 한다.
재발 방지 방법:
조인 조건 없는 JOIN은 항상 “증폭 위험”으로 보고, 목적이 분명할 때만 사용한다.
실무 핵심 포인트
이번 실습의 가장 중요한 교훈은 아래 한 문장으로 정리됩니다.
JOIN은 문법보다 관계가 중요하고, 관계를 모르면 결과는 거의 반드시 왜곡된다
즉, 데이터 분석 실무에서는 조인을 빨리 쓰는 것보다 먼저 아래를 점검해야 합니다.
- 키가 유일한가
- 양쪽 테이블의 grain이 같은가
- 이 조인이 1:1, 1:N, N:N 중 무엇인가
- 이 경우 INNER, LEFT, FULL 중 어떤 조인이 맞는가
이 사고방식이 잡히면 BigQuery뿐 아니라 모든 분석 환경에서 JOIN 오류를 훨씬 줄일 수 있습니다.
결론
핵심 원칙
BigQuery에서 정확한 JOIN을 하려면 조인 전에 키의 유일성과 데이터 관계를 먼저 검증하고, 목적에 맞는 JOIN 타입을 선택해야 한다.
실무 적용 시 주의점
- productSKU 같은 키도 실제로는 유일하지 않을 수 있다
- JOIN 전후 레코드 수를 반드시 비교해야 한다
- INNER JOIN은 교집합만 남기므로 데이터 손실 가능성이 크다
- LEFT JOIN + NULL 필터는 누락 데이터 조사에 매우 유용하다
- CROSS JOIN은 결과를 곱셈처럼 증폭시키므로 의도할 때만 써야 한다
- 조인 전 deduplication이 가장 강력한 예방책이다
다음 학습 단계 제안
다음에는 이 결과를 기반으로 스타 스키마 설계, Fact/Dimension 분리, Looker Studio 연결까지 확장해보면 좋습니다.
'서버 구축·실습' 카테고리의 다른 글
| GCP Application Load Balancer와 Autoscaling을 함께 구성하는 방법 (실습으로 이해하는 트래픽 분산 구조) (0) | 2026.03.27 |
|---|---|
| BigQuery에서 날짜 파티션 테이블을 만드는 방법: 쿼리 비용과 성능을 줄이는 실습 가이드 (0) | 2026.03.27 |
| BigQuery에서 JSON·ARRAY·STRUCT를 다루는 방법: 중첩 데이터 완전 이해 실습 (0) | 2026.03.26 |
| GCP Vision API로 이미지에서 텍스트 추출하고 번역하는 방법 (OCR 실습 완전 가이드) (0) | 2026.03.25 |
| GCP AutoML로 이미지 분류 모델 만드는 방법 (Cloud Vision API 실습 기반 완전 가이드) (0) | 2026.03.25 |



